![图片[1]-replay中文汉化版 AI翻唱训练模型 音频人声分离 软件下载-音浪网-音乐制作系统办公资源](https://www.yinlaa.com/wp-content/uploads/2025/04/d98b9c45fc20250420224713.png)
说明
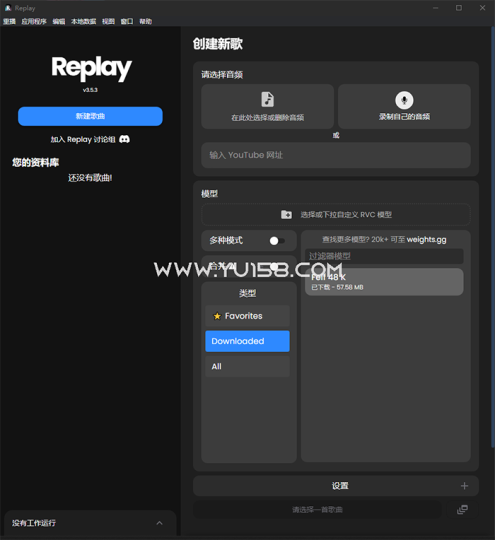
然后进去应用主界面点击【NEW SONG】
在【Create New AI Cover】-【Select Audio】-【SeIect or drop audio here】
可以上传你的原始音乐文件
当然如果你想当场录制你自己的可以选【Record your own】
如果你只是想对原始音乐进行人声和伴奏的AI分离
下面的模型功能模块【Model】就不用管
如果你是需要进行AI翻唱就需要选择一个模型
我这边选择了之前使用过的AI实时变声器中若干模型做一下测试
点击【Select or drop custom RVC model】导入模型文件
导入成功的模型会显示在下面的【DownIoaded】中
我们可以选择其中一个模型
当然如果你想一次性跑多个模型进行翻唱
可以开启上面的【Multi-Model】
然后在【DownIoaded】勾选多个模型
然后点击设置【Settings】
然后根据自己的需要调整一下
比方说我这边需要的是把原始音乐从男声转化成模型中的女声
那么我就把【RelativePitch】调整为正12左右
如何是女声转化成男声就调整为负12左右
不变性的话就用默认的0
【De Echo & Reverb】勾选后可以从人声轨道移除回声和混响
再下面就是高级设置
其中渲染设备【Render Device】
如果你的电脑有Nvidia显卡就选【CUDA】
这样跑起来会比较快耗时较短
如果你的电脑没有Nvidia显卡就选【CPU】
这样跑起来会比较慢耗时较长
其它搞不懂的就直接照抄我的作业
全部设置好后会出现【CREATE SONG】按钮
点击即可开始
跑完后在左边会展示出对应文件列表
打开就能看到各个模型生成的AI翻唱歌曲以及分离出来的人声和伴奏
下载地址
© 版权声明
THE END